FinOps 101 no RTM OpenShift Autopilot: Comece a controlar custos de containers
Introdução
Utilizar serviços de cloud sempre traz desafios, especialmente quando o modelo de cobrança é baseado em uso. Quanto maior a flexibilidade, maior a necessidade de controle e quando falamos de containers, essa volatilidade aumenta ainda mais. Pensando nisso, escrevi este artigo para apresentar as principais boas práticas de FinOps aplicadas ao nosso serviço de containers, o RTM OpenShift Autopilot, ajudando você a operar com mais eficiência, previsibilidade e consciência de custos.
Modelo de cobrança
Quando falamos de FinOps em containers, tudo começa com entender como o custo é formado. No RTM OpenShift Autopilot, o modelo de cobrança é direto: você paga pelos limits configurados nos seus deployments, StatefulSets e ou pods. Parece simples, mas é aqui que muita gente se perde — porque escolher limits aleatórios ou superdimensionados é o atalho mais rápido para estourar o orçamento.
O ponto é que, diferentemente de máquinas virtuais tradicionais, containers são extremamente dinâmicos. Eles escalam, reduzem, reiniciam, são criados e destruídos o tempo todo. Por isso, o dimensionamento correto vira parte crítica da disciplina de FinOps. E quando você domina isso, a conta começa a trabalhar a seu favor.
No Autopilot, práticas como ajustar limits, remover workloads ociosos, usar escalonamento automático e contratar reservas de recursos formam um conjunto poderoso para ter previsibilidade e eficiência ao mesmo tempo. É o equilíbrio entre performance, custo e responsabilidade — exatamente o que o FinOps prega.
Mas afinal, o que é “Request”?
O Request é o mínimo de CPU e memória que o pod precisa para ser agendado no cluster.
Ele diz ao scheduler: “reserve pelo menos isso para mim”.
Diferente do Limit, o Request não controla o uso real — o pod pode consumir mais do que o Request enquanto estiver abaixo do Limit.
No modelo do RTM Openshift Autopilot, quem define o custo é o Limit, não o Request.
Ou seja:
- O Request NÃO influencia preço.
- Não tem o mesmo peso financeiro que em outros serviços baseados em custo por worker-node.
Mas afinal, o que é “Limit”?
No mundo de containers e Openshift/Kubernetes, o Limit é simplesmente o teto máximo de recurso que um pod pode usar. É como definir até onde ele pode ir.
Pense assim: o Limit é o limite superior de CPU e memória que o container está autorizado a consumir.
Se ele tentar ultrapassar isso, o RTM Openshift Autopilot entra em ação:
- Para CPU: o consumo é “estrangulado” (throttling). Ele até tenta usar mais, mas o cluster não deixa.
- Para Memória: se ultrapassar o limite, o container pode ser encerrado (OOMKilled).
Exemplo de configuração de limit
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpd-deployment
labels:
app: httpd
spec:
replicas: 3
selector:
matchLabels:
app: httpd
template:
metadata:
labels:
app: httpd
spec:
containers:
- name: httpd
image: registry.access.redhat.com/ubi8/httpd-24:latest
ports:
- containerPort: 8080
resources:
limits:
cpu: "250m"
memory: "512Mi"Método de acesso
O RTM OpenShift Autopilot oferece dois caminhos de acesso, cada um pensado para perfis diferentes de usuários e para tipos distintos de operações. O primeiro é a interface gráfica (UI), ideal para quem prefere visualizar recursos, navegar entre workloads e realizar ações de forma rápida e intuitiva. Já o segundo é o acesso via API utilizando o oc CLI, voltado para quem busca agilidade, precisão e automação — geralmente usuários mais avançados ou acostumados com ambientes Kubernetes e pipelines.
É importante destacar que algumas operações podem ser mais simples, mais completas ou até mesmo exclusivas de um dos métodos. A UI facilita muito o dia a dia operacional e o entendimento visual do cluster, enquanto o oc CLI permite comandos diretos, scripts, integrações e workflows automatizados. No fim das contas, a escolha do método depende não só da preferência pessoal, mas também do nível de maturidade técnica e da natureza da tarefa.
Acesso pela interface gráfica
- Acesse a URL do RTM OpenShift Autopilot fornecida pela RTM.
- Em Log in with, selecione a opção Clientes.
- Insira seu usuário e senha.
- Pronto — você estará conectado na interface gráfica do Autopilot.
Acesso pela API (oc CLI)
- No canto superior direito da UI, clique no seu usuário.
- Selecione Copy login command.
- Clique em Display token para visualizar o token de acesso.
- Copie o comando exibido e cole no seu terminal — com o
ocCLI já instalado.
Se você ainda não tem o
ocCLI instalado, você pode baixar no link da Red Hat:
https://docs.redhat.com/en/documentation/openshift_container_platform/4.8/html/cli_tools/openshift-cli-oc
Visualizando seus limits
Entender onde estão configurados os limits — e principalmente acompanhar seu uso real — é uma etapa fundamental no processo de FinOps dentro do RTM OpenShift Autopilot. Você pode visualizar essas informações tanto pela interface gráfica quanto via oc CLI. Cada método fornece um nível diferente de profundidade e detalhe.
Versão gráfica
ara uma visualização rápida e intuitiva dos limits configurados e do consumo atual, a interface gráfica é o caminho mais simples.
- No menu lateral, selecione Developer.
- Em seguida, clique em Observe.
- Dentro de Dashboard, você encontrará painéis como:
- CPU Quota
- Mem Quota
Esses painéis mostram não apenas os valores dos limites alocados, mas também a porcentagem de consumo — algo extremamente útil dentro de uma estratégia de FinOps. Esse contraste entre limit configurado e uso real ajuda a identificar onde há superdimensionamento, desperdício ou oportunidade de otimização.


Versão linha de comando
Os comandos a seguir ajudam a visualizar de forma global e rapida os limits de todos os deployments, statefulsets e ou Pods do namespace.
Visualizando limits por Pod
oc get pod -o custom-columns=POD:.metadata.name,CONTAINER:.spec.containers[*].name,STATUS:.status.phase,CPU-LIMITS:.spec.containers[*].resources.limits.cpu,MEMORY-LIMITS:.spec.containers[*].resources.limits.memory | column -tVisualizando o uso por Pod
oc adm top podVisualizando limits por Deployment
oc get deploy -o custom-columns=DEPLOYMENT:.metadata.name,REPLICAS:.spec.replicas,CPU-LIMITS-PER-POD:.spec.template.spec.containers[*].resources.limits.cpu,MEMORY-LIMITS-PER-POD:.spec.template.spec.containers[*].resources.limits.memory | column -tVisualizando limits por StatefulSets
oc get statefulset -o custom-columns=STATEFULSET:.metadata.name,REPLICAS:.spec.replicas,CPU-LIMIT-PER-POD:.spec.template.spec.containers[].resources.limits.cpu,MEMORY-LIMIT-PER-POD:.spec.template.spec.containers[].resources.limits.memory | column -tImportante: os limits exibidos tanto no comando de Pods quanto no comando de Deployments representam o limit configurado para cada Pod individualmente. O comando de Deployment e Statefulset não calcula o total do workload. Portanto, para estimar o consumo total do Deployment e Statefulset, é necessário multiplicar o limit de cada Pod pelo número de réplicas configuradas.
Soft e Hard quotas
Para gerenciar Limits de forma eficiente — e manter o uso de recursos sob controle — é importante definir algumas regras e travas dentro do seu projeto. No OpenShift, isso acontece através de duas categorias principais: Soft Quotas e Hard Quotas.
Cada uma cumpre um papel diferente na estratégia de FinOps. Enquanto as Soft Quotas funcionam como alertas para avisar que você está se aproximando do limite, as Hard Quotas atuam como bloqueios reais, impedindo a criação de novos recursos quando o teto é atingido.
Hard mode: Controlando o consumo com ResourceQuota
Se você quer colocar o cluster para trabalhar a seu favor no controle de custos, o ResourceQuota é o modo Hard da história. Ele permite definir um limite máximo de recursos que o seu projeto pode consumir — como CPU, memória ou número de pods. Quando esse limite é atingido, o OpenShift simplesmente bloqueia novas alocações. Nada de criar novos pods, nada de consumir mais do que foi combinado.
Na prática, isso ajuda a manter um teto financeiro e evita surpresas desagradáveis no final do mês. Você define o máximo, e o cluster garante que ninguém passe dele.
Se você usar ResourceQuota de forma muito rígida, pode acabar bloqueando comportamentos dinâmicos, como o Horizontal Pod Autoscaler (HPA). Como o HPA cria novas réplicas automaticamente, ele pode bater no limite antes de escalar — ou simplesmente não escalar.
Para a criação de um ResourceQuota é necessario abrir um chamado através do portal de atendimento da RTM descrevendo os parametros de CPU e Memoria desejavel e o nome do Project / Namespace.
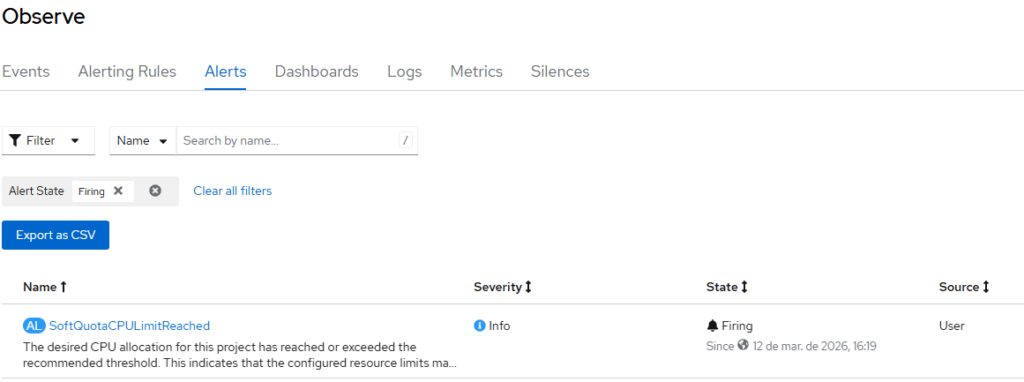
Soft mode: Monitorando o consumo com Alerts
No Soft Mode, você não impede o cluster de consumir mais recursos — mas cria uma camada de alertas inteligentes para saber quando está chegando perto do limite planejado.
Com o OpenShift Monitoring, é possível configurar notificações quando um determinado valor de uso é alcançado ou ultrapassado. Ele não trava o provisionamento, não bloqueia Pods e não interfere no autoscaling. O papel dele aqui é visibilidade: te avisar antes que o consumo saia do controle.
É uma abordagem ideal para times que querem manter liberdade operacional, mas sem abrir mão de governança e boa disciplina FinOps. Afinal, saber com antecedência que você está prestes a estourar um limite permite ajustar rapidamente os limits, revisar réplicas ou até repensar o dimensionamento dos seus workloads.
Monitorar a superutilização
Quando um alerta de superutilização dispara, os cenários mais prováveis são:
- Demanda real aumentou, exigindo revisão de limites ou estudo de reservas;
- Bug ou comportamento inesperado elevando o uso sem necessidade;
- Ambiente mudou, e o alerta precisa ser ajustado para a nova realidade.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: softquota-high-usage-alerts
namespace: <namespace>
spec:
groups:
- name: soft-quota-thresholds
rules:
- alert: SoftQuotaCPULimitReached
expr: |
sum by (namespace) (
kube_pod_container_resource_limits{resource="cpu", unit="core"}
) >= <total CPU>
for: 7d
labels:
severity: info
category: finops
resource: cpu
annotations:
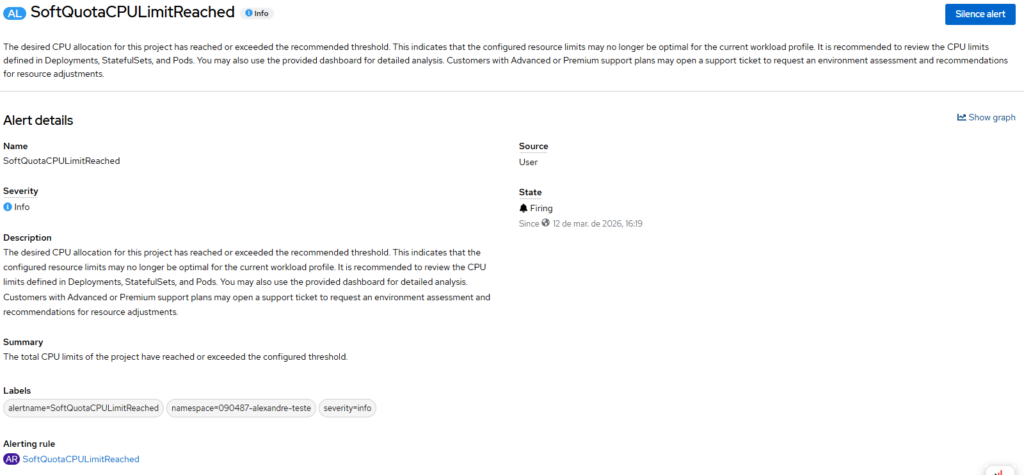
summary: "The total CPU limits of the project have reached or exceeded the configured threshold."
description: "The desired CPU allocation for this project has reached or exceeded the recommended threshold. This indicates that the configured resource limits may no longer be optimal for the current workload profile. It is recommended to review the CPU limits defined in Deployments, StatefulSets, and Pods. You may also use the provided dashboard for detailed analysis. Customers with Advanced or Premium support plans may open a support ticket to request an environment assessment and recommendations for resource adjustments."
- alert: SoftQuotaMemoryLimitReached
expr: |
sum by (namespace) (
kube_pod_container_resource_limits{resource="memory", unit="byte"}
) >= <total memory (GiB)> * 1024 * 1024 * 1024
for: 7d
labels:
severity: info
category: finops
resource: memory
annotations:
summary: "The total Memory limits of the project have reached or exceeded the configured threshold"
description: "The desired Memory allocation for this project has reached or exceeded the recommended threshold. This indicates that the configured resource limits may no longer be optimal for the current workload profile. It is recommended to review the Memory limits defined in Deployments, StatefulSets, and Pods. You may also use the provided dashboard for detailed analysis. Customers with Advanced or Premium support plans may open a support ticket to request an environment assessment and recommendations for resource adjustments."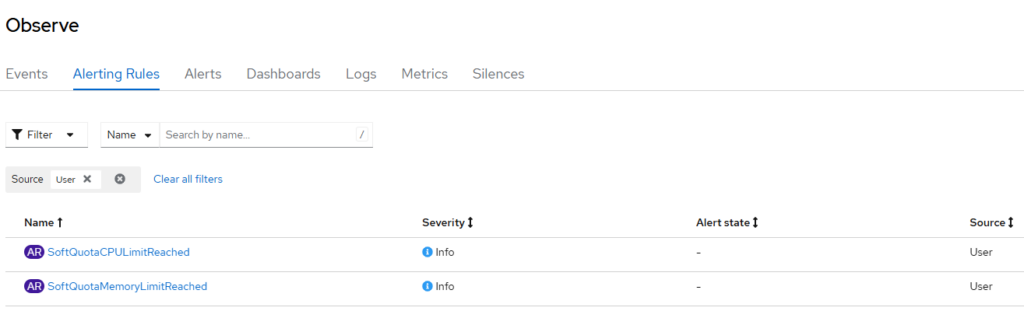
Monitorar a subutilização
Quando um alerta de subutilização dispara, os cenários mais prováveis são:
- O limite está maior do que o necessário;
- O ambiente mudou e os valores não foram atualizados;
- O workload está ocioso ou com carga reduzida;
- Há uma oportunidade real de downgrade de limits e economia financeira.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: softquota-low-usage-alerts
namespace: <namespace>
spec:
groups:
- name: finops-soft-low-usage-namespace
rules:
- alert: soft-low-usage-alert-cpu-namespace
expr: |
(
avg_over_time(
(
(
sum by (namespace) (
rate(container_cpu_usage_seconds_total{namespace="<namespace>, container!=""}[5m])
)
)
/
(
sum by (namespace) (
kube_pod_container_resource_limits{namespace="<namespace>", resource="cpu", unit="core"}
)
)
)[30d:]
) < 0.30
)
and
(
quantile_over_time(
0.95,
(
(
sum by (namespace) (
rate(container_cpu_usage_seconds_total{namespace="<namespace>", container!=""}[5m])
)
)
/
(
sum by (namespace) (
kube_pod_container_resource_limits{namespace="<namespace>", resource="cpu", unit="core"}
)
)
)[30d:]
) < 0.50
)
for: 1h
labels:
severity: info
category: finops
resource: cpu
annotations:
summary: "CPU underutilization in namespace over 30 days"
description: "30-day average usage/limit < 30% and 30-day p95 < 50%. Indicates overprovisioning and a clear opportunity to reduce limits. Review Deployments/StatefulSets and consider limits downgrade to optimize costs."
- alert: soft-low-usage-alert-memory-namespace
expr: |
(
avg_over_time(
(
(
sum by (namespace) (
container_memory_working_set_bytes{namespace="<namespace>", container!=""}
)
)
/
(
sum by (namespace) (
kube_pod_container_resource_limits{namespace="<namespace>", resource="memory", unit="byte"}
)
)
)[30d:]
) < 0.35
)
and
(
quantile_over_time(
0.95,
(
(
sum by (namespace) (
container_memory_working_set_bytes{namespace="<namespace>", container!=""}
)
)
/
(
sum by (namespace) (
kube_pod_container_resource_limits{namespace="<namespace>", resource="memory", unit="byte"}
)
)
)[30d:]
) < 0.55
)
for: 1h
labels:
severity: info
category: finops
resource: memory
annotations:
summary: "Memory underutilization in namespace over 30 days"
description: "30-day average usage/limit < 30% and 30-day p95 < 50%. Indicates overprovisioning and a clear opportunity to reduce limits. Review Deployments/StatefulSets and consider limits downgrade to optimize costs."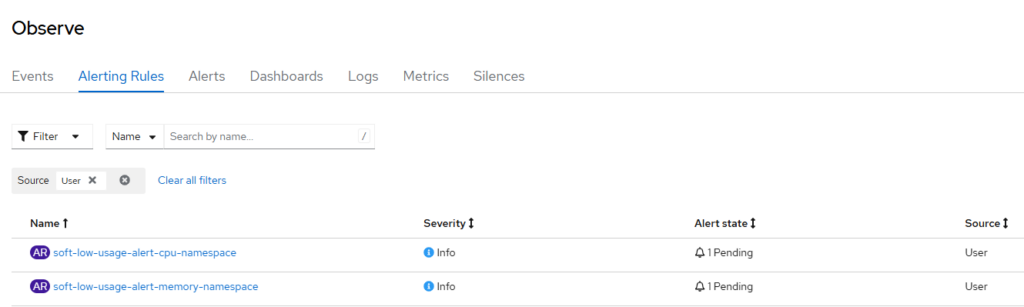
Visualização de alertas
Escalonamento programado: Quando o HPA não é suficiente
Ambientes “não-produtivos” (ex: homologação, staging, UAT, desenvolvimento) geralmente não precisam ficar ligados o dia inteiro, mas acabam consumindo recursos como se fossem produção — e aí o custo sobe sem necessidade. Como o HPA não escala workloads para zero e reage apenas baseado no uso de recurso, ele não resolve esse tipo de cenário. É aqui que entra o escalonamento programado: um CronJob simples que “liga e desliga” seus Deployments na hora certa, evitando que workloads ociosos rodem 24×7 e garantindo economia real no RTM OpenShift Autopilot.
Criando um ServiceAccount
Para executar workloads de automação, o ideal é usar um ServiceAccount. Rodar esse tipo de tarefa com usuários comuns não só é arriscado, como também dificulta o controle de permissões e auditoria. Com um ServiceAccount, você garante que o job tenha apenas os acessos necessários e mantém o ambiente mais seguro e previsível.
oc create serviceaccount sa-scheduler-scaler -n <namespace>Definindo permissões (Role & RoleBinding)
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: scheduler-scaler-role
namespace: <namespace>
rules:
- apiGroups: ["apps"]
resources: ["deployments","deployments/scale"]
verbs: ["get", "update", "patch"]apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: scheduler-scaler-rolebinding
namespace: <namespace>
subjects:
- kind: ServiceAccount
name: sa-scheduler-scaler
namespace: <namespace>
roleRef:
kind: Role
name: scheduler-scaler-role
apiGroup: rbac.authorization.k8s.ioAgendando o escalonamento
apiVersion: batch/v1
kind: CronJob
metadata:
name: scale-up
namespace: <namespace>
spec:
schedule: "0 8 * * *" # todos os dias às 08:00 da manhã.
timeZone: "America/Sao_Paulo"
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 0
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
spec:
serviceAccountName: sa-scheduler-scaler
containers:
- name: scaler
image: registry.redhat.io/openshift4/ose-cli
command:
- /bin/sh
- -c
- oc scale deployment httpd-deployment --replicas=<qtd.replicas> -n <namespace>
restartPolicy: NeverapiVersion: batch/v1
kind: CronJob
metadata:
name: scale-down
namespace: <namespace>
spec:
schedule: "0 20 * * *" # todos os dias às 20:00 da noite.
timeZone: "America/Sao_Paulo"
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 0
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
spec:
serviceAccountName: sa-scheduler-scaler
containers:
- name: scaler
image: registry.redhat.io/openshift4/ose-cli
command:
- /bin/sh
- -c
- oc scale deployment httpd-deployment --replicas=0 -n <namespace>
restartPolicy: NeverBonus Track: Hora de falar de Storage
Por mais que CPU e memória sejam os recursos que mais preocupam no RTM OpenShift Autopilot — e, na verdade, em qualquer ambiente de containers — o armazenamento também merece bastante atenção. No Autopilot, os PV/PVC são cobrados pelo tamanho provisionado do volume, que funciona como o “limit” do storage: é a capacidade declarada que aquele volume pode suportar.
Quando falamos de FinOps voltado para storage, existem dois pontos essenciais de monitorar para manter o custo sob controle. O primeiro é a existência de volumes sem vínculo, que são PVs que já não estão mais associados a nenhum Pod, Deployment ou StatefulSet, mas continuam provisionados e gerando cobrança. O segundo ponto é o superdimensionamento: volumes criados com muito mais capacidade do que o necessário — algo comum em projetos que ainda estão amadurecendo ou quando o planejamento inicial não reflete a realidade atual do uso.
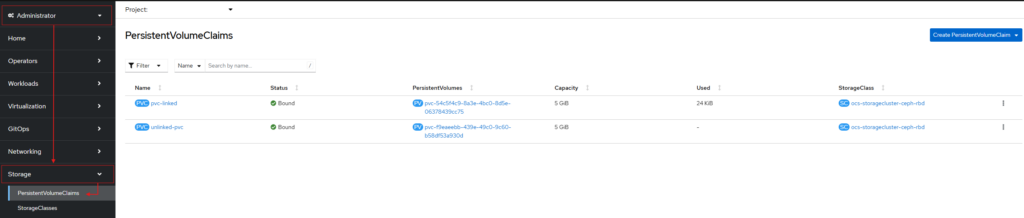
Monitorando volumes sem vínculo
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: unlinked-pvc-alerts
namespace: <namespace>
spec:
groups:
- name: storage.finops.pvc
rules:
- alert: UnlinkedPersistentVolumeClaim
expr: |
(
kube_persistentvolumeclaim_status_phase{namespace="<namespace>", phase="Bound"} == 1
)
unless on(namespace, persistentvolumeclaim)
(
kube_pod_spec_volumes_persistentvolumeclaims_info{namespace="<namespace>"}
and on(namespace, pod)
kube_pod_status_phase{namespace="<namespace>", phase=~"Pending|Running|Unknown"} == 1
)
for: 7d
labels:
severity: info
category: finops
resource: storage
annotations:
summary: "Unlinked PVC detected (Used by: none)"
description: "The PersistentVolumeClaim '{{ $labels.persistentvolumeclaim }}' in namespace is in the Bound phase but is not linked to any active Pod (Used by: none). This indicates potential unused storage cost."Monitorando volumes subutilizados
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: low-usage-alert-pvc
namespace: <namespace>
spec:
groups:
- name: storage.finops.pvc
rules:
- alert: LowUsagePersistentVolumeClaim
expr: |
(
(
kubelet_volume_stats_used_bytes{namespace="<namespace>"}
/
kubelet_volume_stats_capacity_bytes{namespace="<namespace>"}
) < 0.5
)
and on (namespace, persistentvolumeclaim)
(
kube_pod_spec_volumes_persistentvolumeclaims_info{namespace="<namespace>"}
* on (namespace, pod) group_left
max by (namespace, pod) (
kube_pod_status_phase{namespace="<namespace>", phase=~"Running|Pending"} == 1
)
)
for: 30d
labels:
severity: info
category: finops
resource: storage
annotations:
summary: "Low-usage PVC detected (<50%)"
description: >-
The PersistentVolumeClaim '{{ $labels.persistentvolumeclaim }}' in namespace '{{ $labels.namespace }}'
has sustained utilization below 50% while being linked to active Pod(s).